Custom File Signature rules
This is mainly for engineers and data recovery experts although any enthusiast can easily pick it up and start playing with it !
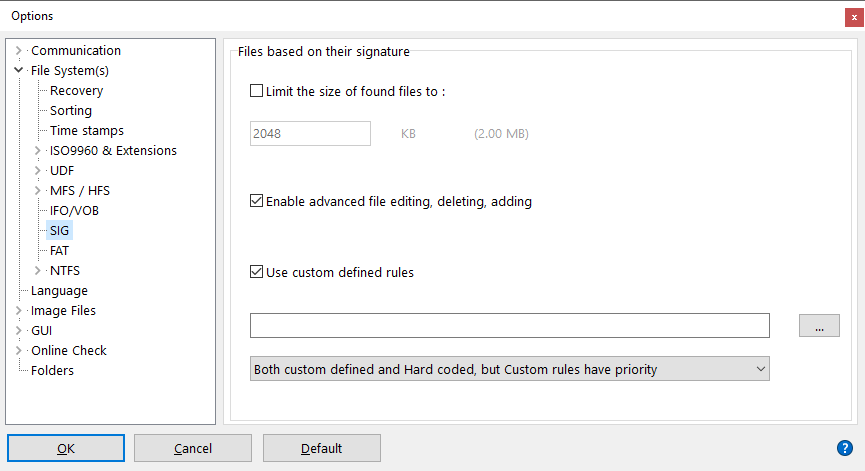
IsoBuster is able to load and use custom defined rules to find files based on the defined signature.
*.rules files are pure text files that contain a rule per line and they can be stored anywhere from where you can load them. Or simply put them in the /plugins/ folder
You can select the *.rules file IsoBuster needs to use via options. See screenshot above.
When the checkbox "Use custom defined rules" is checked, IsoBuster loads and uses the defined *.rules file on every "Find missing files and folders" to help populate the "Files found based on their signature" File system / List.
There are three possible scenario's for using custom rules. They can be selected via the drop down selection at the bottom of the window (See screenshot above) :
- Only the custom defined rules.
- Both the hard coded (program embedded) rules and the custom rules, but first the custom rules are checked, and if no match, the hard coded rules are used.
- Both the hard coded (program embedded) rules and the custom rules, but first the hard coded rules are used, and if no match, the custom rules are tried.
*.rules files contain a rule per line.
Because parsing a text file is not as fast as embedded code, the syntax of each line is very strict ! The moment the syntax doesn't follow the rules outlined below, the test will either fail or possibly trigger a false positive.
It is best to only put valid rules in a *.rules file and keep comments etc. outside the file, in a second file perhaps, as it will improve the speed.
To test a rule, it can help to load the target type file in IsoBuster (as a presumed image file) and run "Find Missing files and folders". If the defined signature is found at address (LBA) 0, then the rule works.
Every rule is tested against every block that is read.
So for every block the entire list of all the rules will be checked before going to the next block etc.
If the media is optical (CD, DVD, BD) the rule will be triggered on every 2048 bytes. If it is a Hard Drive or USB stick, the rule will be tested against every 512 bytes-block or every 4096 bytes block on 4kn drives.
The start offset is 0 in every block, unles IsoBuster detected a file system structure that precedes a possible file inside the same block. E.g. files that are embedded in NTFS or FAT file descriptors.
Blocks with certain file system structures that don't contain file data are skipped and will not be tested further.
Each block is tested against every rule in the rules file until a line matches the data, after which the next block is tested.
Every rule works per byte, starts at index 0 of the presented block and proceeds to the next byte once a byte has been tested against the value in the rule.
Every command on the line is escaped with a backslash and is only one character in size. So backslash and command combined are always 2 characters.
The values and commands in a rule / line:
\%
A comment [Functionality available since IsoBuster 4.7]
Anything that follows this command on a line is ignored. Anything before it is processed like normal. So don't add leading spaces, they will only consume processing time during the scan
\i()
Assign a unique ID to a line [Functionality available since IsoBuster 4.7]
This enables other commmands, that are ID aware, to apply their magic to this particular line or rather to the file that was found due to this line
An ID can not be 0 (zero) and must be smaller (or equal) than 65535 (0xFFFF)
\e()
End a previously found file (that is still open) [Functionality available since IsoBuster 4.7]
This command is ID aware (provide the ID between the brackets)
When a file was found through its signature, but no new signature has been detected yet, and hence the file's size is still growing, this command can be used to end the file
Ideally issued with an ID that corresponds to another line (and hence type of file)
If no value/id is provided between the brackets, this command 'ends' any found file that is still growing.
In the latter scenario it is used to detect signatures that end any file, but are not part of files themselves.
\c()
Concatenate to a previously found file (that is still open) [Functionality available since IsoBuster 4.7]
This command is ID aware (provide the ID between the brackets)
When the signature in this line matches with the data, instead of 'ending' previously found file (that is still open and growing), and starting a new one, previously found file will simply keep growing instead
The data is hence concatenated to previously found file. This may seem like a useless command, but it is particularly useful for dealing with recurring signatures in files.
Instead of finding x files each time the signature is detected, it helps find one file that contains the x signatures.
For instance line \i(1)\c(1)\x00\x00\x01\xba\|.VOB assures that not x VOB files with 2048 bytes are found, but instead one file is found with x * 2048 bytes
\#
Finding the size of a file is guess work. Generally the size of a file is determined by the start location of next file or by a file-system structure that is found.
If IsoBuster runs into a file system structure and hence assumes previously found file ends here, it will pass a boolean parameter to the next test/block indicating this.
This boolean parameter can be used to only trigger when the boolean value is true. Command \# does exactly that.
For instance, assume you know a file starts with two byte values \x1F\x8B
However, this signature is so generic it will be found lots of times inside existing files, causing lots of false positives and cutting previously found files short in size.
Such a rule is best left out, but you could still allow it, but only when IsoBuster signals that previously found file ended already anyway.
In that case you could use rule \#\x1F\x8B\|.gz
Make \# the first command on a line if you decide to use it. This will greatly improve speed.
\|
For speed reasons, each line starts with the test and is terminated with command \|
\| is followed by the extension, for instance: \#\x1F\x8B\|.gz
and optionally the extension can be followed by | file-size in bytes. This can be used for when you know how big the file really is. For instance: \#\x01\x02\|.gz|1000
\x
Every byte-test in the rule can be specified in two ways. As hexadecimal value \x00 or as ASCII value (see further).
The syntax is very strict. There must always be two characters in a hexadecimal notation and the range is (obviously) \x00 - \xFF
It is also possible to test only a nibble. In that case use ? for the nibble you don't want to test. E.g. \0x?3 will match byte values 0xF3, 0xE3, 0xD3, ..., 0x23, 0x13, 0x03.
\x?? means you don't want to test this byte at all, it can have any value, it is the same as skipping a byte. E.g. in sequence: \0x00\0x01\x??\x01\x00 bytes 0,1,3 and 4 must match, byte 2 can have any value.
PS. Do not use the nibble wildcard ? in byte values that need to be smaller or bigger (and or equal) than. So not in combination with \> or \< or \>\= or \<\= because it will have undefined effects and hence will be untrustworthy.
ASCII character
All the readable characters between byte value 32 and 126 can be used to test against.
For instance: GIF\|.gif is a valid test, and is essentially the same as: \x47IF\|.gif or G\x49F\|.gif etc.
\ is also a valid character but because the backslash is used to escape special values and commands, you need to double the \ when using it to test as a test value: \\
\v()
Compare the byte value at current offset with a byte value at the offset defined with \v()
The value between the round brackets is either decimal or hexadecimal. The latter requires the notation 0x , for instance \v(0x0F) tests if current tested byte value matches the byte value at offset 15. This command can be combined with \> \< \<= and \>=
For instance this example: \v(5)\x10 tests if the first byte at offset 0 matches the byte at offset 5 and if so, tests if the second byte at offset 1 matches 0x10
\p()
Change the absolute Position / Offset in the datablock before doing the next test
For instance: \p(3)\x01\x02 means that the offset is changed from 0 to 3, and hence byte 3 in the data block must match 0x01 and byte 4 must match 0x02
You can jump to any position in the data block but you need to stay within the boundaries of the block or the test will fail.
You can jump back and forth if that makes sense for whatever reason. For instance, for speed reasons, test a very strict and certain byte value further in the block and only if that matches jump back to the beginning of the block and test other bytes.
For instance: \p(100)PP\p(0)\f(100,OK) tests for the existence of "P" at offset 100, and "P" at offset 101, and if that is true continues to search through the first 100 bytes for text "OK"
The value between the round brackets is either decimal or hexadecimal. The latter requires the notation 0x , for instance \p(0xFF) jumps to offset 255 etc.
\s()
Change the position by skipping an amount of bytes from current position.
For instance earlier used example: \0x00\0x01\x??\x01\x00 could also be written as: \0x00\0x01\s(1)\x01\x00
The value between the round brackets is either decimal or hexadecimal. The latter requires the notation 0x , for instance \s(0x10) skips 16 bytes.
It is also possible to skip a negative amount of bytes (only using decimal notation).
For instance \s(-1) skips back a byte. This can be useful to test a single byte value against several different parameters. E.g. if a byte value is between two values.
Eg. \>\x10\s(-1)\<\=\x20 tests if a byte value is bigger than 16 and smaller or equal than 32.
\=
= is implied and redundant.
Every byte test assumes the byte in the data block matches the byte in the rule
However, if put behind \> or \< for instance \>\= or \<\= it translates to >= or <=
\>
Put \> before a byte value, e.g. \>\x33 means the byte in the data block must be bigger than 0x33 (instead of must be equal to 0x33)
When immediately followed by \=, it translates to >= e.g. \>\=\x33 which means the byte in the data block must be bigger or equal than 0x33
\<
Put \< before a byte value, e.g. \<\x50 means the byte in the data block must be smaller than 0x50 (instead of must be equal to 0x50)
When immediately followed by \=, it translates to <=
\f()
Find a condition starting from the start offset, over a defined range. If the condition is met, the next offset is located just after the condition that was searched for.
The syntax must be \f(range,condition)
Keep the range inside the block. The condition can be pretty much anything that can be defined by all the commands and values described here, except other \f() commands.
\f() commands can not be nested.
For instance \f(100,Peter) will search for "Peter" inside a block, starting from offset 0 and within the range of 100 bytes.
For instance \p(10)\f(100,Peter) will start the same search from offset 10 over a range of 100 bytes
For instance \p(10)\f(100,Peter) aka IsoBuster\x00 will look for "Peter" and if found will check if it is followed by null terminated " aka IsoBuster"
Use this command only when you need to. For instance as single rule in a rules file, to search for something very specific, because this command can considerably slow down the search.
Of course if you start the rule with a byte at a fixed position needing to match a certain value first, the search will only be performed if at least that fixed location value matches. That may reduce the search being called considerably
In this example: \xEF\xBB\xBF\f(4,<?xml)\|.xml there can be up to 4 trailing (blank) characters before the <?xml tag in this UTF8 xml file.
\o()
OR different tests. Not just byte values (which is of course possible) but entire sequences if you want.
The value between the round brackets is the amount of ORed tests that needs to be done.
\o() also needs to be used between every possible test of the OR test sequence and also needs to trail the OR test.
E.g. \o(2)A\o()B\o() tests if the byte at offset 0 is either ASCII A or B
The value between the round brackets is either decimal or hexadecimal. The latter requires the notation 0x , for instance \p(0x03) means 3
For instance \o(2) means that there are two tests that need to be done.
If the first test doesn't match, the second test needs to be performed. If the first one matched, the second one is ignored. This can also be done with more tests, e.g. 4 tests: \o(4). Values 0 and 1 are impossible values however and will fail the entire rule !
\o() also accepts a single-character user-defined code. Sort of a bookmark if you will. The syntax then is: \o(value,code)
The user-define-code is not necesary for normal OR tests but if you want to nest OR tests inside OR tests, then it is absolutely necessary !
For instance \o(2,a) means there are two tests that need to be ORed and the user defined code is 'a'
The syntax with user-defined-code can be used at all times but it is only absolutely needed when you want to execute nested OR tests.
In order for the rule-parser to make sense of nested ORs you need to use codes the moment you start nesting OR tests.
The \o() syntax is very strict and must contain \o() between every test and at the end of the sequence.
In case of a code, it must contain the code between the round brackets. In case of no code, there must be nothing between the round brackets.
For instance: \o(3)\x11\o()\x22\o()\0x33\o() This means that the byte value at given offset can be either 0x11 or 0x22 or 0x33
In case a code had been used, the syntax must be: \o(3,a)\x11\o(a)\x22\o(a)\0x33\o(a) for the same test.
An important side effect of the \o() test is that the offset does not change after the test. For every other test the offset automatically increases with 1. So in a test sequence of 3 bytes (e.g. \x00\x01\x02 ) the first byte will be checked, next the second byte (so the offset moved up one), next the third one (so again the offset move up one) and so on.
After an \o() test however, the offset inside the block of data is still at the same point where it was before the \o() test. The reason for this is because every sub-test in the OR test can be of variable length, and every sub-test can take you anywhere inside the block of data using \p() and \s(). Since you can't know what sub-test succeeded and where the pointer/offset ended up, before next test is executed, you need to position the offset again.
For instance: \o(3,a)\x11\x12\x13\o(a)\x22\o(a)\0x33\s(5)\x33\o(a) If the first sub-test succeeded the offset would have moved up 3 bytes. However if the second test succeeded the offset would have moved up only 2 byte. If both test 1 and 2 failed but the third one succeeded the pointer would have moved up 6 bytes. So ... since this is an unknown, after the \o() test the pointer is back to where it was before the test started.
In this example: \o(3)\x11\o()\x22\o()\0x33\o()\s(1)0x44\|.blah byte 0 can be either 0x11 or 0x22 or 0x33, and if that condition is met, \s(1) increases the offset with one so that byte 1 can be tested against value 0x44
An example for a nested \o() test is: \o(3)\x11\o()\x22\o(2,a)\x23\o(a)\x24\o(a)\o()\0x33\o()
Use of the code helps the parser figure out which part belongs to what test.
Every sub test is a test in itself that can use any of the above used commands and values. Just make sure to use mentioned codes if you start nesting \o() e.g. \o(2,c) ...
Just a few real life examples:
LZANIM\|.lza
\xFF\xD8\xFF\o(2)\xE?\o()\xFE\o()\|.jpg
GIF\o(2)8\o()\#\x??\o()\|.gif
\#ID3\|.mp3
MM\x00\x2A\|.kdc
\x4F\x67\x67\x53\x00\x02\x00\x00\x00\x00\x00\x00\x00\x00\|.ogg
SFW/|.sfw
\x60\xEA\o(2)\p(8)\x10\x00\x02\o()\#\x??\o()\|.arj
gzip-\>\=1\s(-1)\<\=9.\>\=1\s(-1)\<\=9.\>\=1\s(-1)\<\=9\|.gz
\xEF\xBB\xBF\f(4,<?xml)\|.xml
MSWIM\x00\x00\|.wim
\x01\p(0x13)\x3E\x40\p(7)\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\|.btd
\x00\p(0x80)DICM\f(200,1.2.840.10008.1.3.10)\p(1)\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\|.dicomdir
\x00\p(0x80)DICM\p(1)\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\|.dcm
%vsm%\s(3)\x00P\x00r\x00o\x00d\x00u\x00c\x00e\x00d\p(0x29)S\x00o\x00f\x00t\x00w\x00a\x00r\x00e\|.vp3
#PES0001\|.pes
\x??Embird Outline Format v\|.eof
\x??\x00\x00\x00\x0A\x00\x00\x0020\|.jef
More on Github